 Jason Burke | February 28, 2023
Jason Burke | February 28, 2023
Recently, I had the opportunity to discuss the future of bioanalytical labs with Dr. Chad Briscoe, VP of Global Bioanalytical Services at Celerion (you can see the interview here). One of the topics we touched on was the opportunity in using predictive analytics to unlock new advances in laboratory sciences. Our discussion served as a reminder of the important role a solid data strategy serves in unlocking these growth opportunities.
Our conversation reminded me of a data strategy paper published in the journal Diagnostics last year called Big Data in Laboratory Medicine—FAIR Quality for AI? The authors argued that laboratories need to invest in digital transformation initiatives that help establish a set of “big data” principles – called FAIR principles – for the aggregation and management of lab-related data.
If you are not familiar with it, FAIR is acronym which stands for Findability, Accessibility, Interoperability, and Reusability. It is a concept that was published in 2016 Nature paper as scientists were grappling with the inherently heterogeneous nature of scientific data collection and management. When different scientists use different methods to collect different data for different purposes, how do you curate reusable data assets?
The concept of reusable data assets is important for every bioanalytical and clinical lab, though it is not unique to labs. Most organizations capture “fit-for-use” data. If they are trying to manage relationships with customers, they use a CRM system to manage the customer record-keeping process. If they are trying to process lab samples, they use LIM systems and lab notebooks to manage the workflow. The unique characteristic of “fit-for-use” data is that the context of the data – where it comes from, what it means, how it is used – is fairly well defined by how the organization is using the data today.
In contrast to “fit-for-use” data, organizations are often challenged to develop data strategies that are “fit-for-any-use.” Aggregating data from source systems changes the available context of the data – the data is no longer directly associated with its business process (i.e., source system, clinical study definition, lab workflow). And since future use cases for the data are unlimited, the design criteria for aggregating the data – what data and metadata is collected, how it is structured, how access rights are managed – require different considerations.
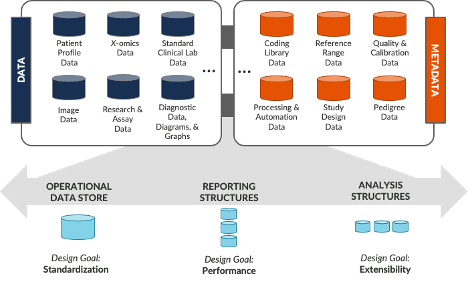
To effectively leverage their growing data repositories beyond today’s analysis and testing, every bioanalytical and clinical lab needs a data strategy that addresses “fit-for-any-use.” FAIR principles are a good starting point for planning, but more explicit requirements are needed to develop real-world solutions. Artificial intelligence opportunities can actually serve as a great catalyst for these requirements, as data leaders are faced with differentiating between three distinct design goals:
- Standardization – how do we provide a standardized way of aggregating and accessing data regardless of source system, physical location, and underlying storage technology? Data warehouses, data lakes, data meshes, data fabrics, and other options can both support and complicate the development of a clear enterprise architecture.
- Performance – how do we implement data models that can support easy, rapid reporting of key performance measures and operational metrics? Data visualization solutions, for example, can put a lot of insights into the hands of end users when their associated data models are designed for high performance.
- Extensibility – how do we design data models that are suitable for large-scale, iterative processing of customized analytical algorithms and logic? With the need to iteratively train machine learning models, subject-specific domain data models are rising importance for many enterprises.
In many ways, bioanalytical and clinical labs are in an ideal position to take advantage of modern digital architectures. The opportunity space can be well characterized by lab leaders, and existing experiences with LIM systems and lab notebooks provide a sound foundation from which to grow. I’m excited to see the innovative AI opportunities that will naturally emerge as more organizations develop these growth-oriented data strategies.


